


Introduction
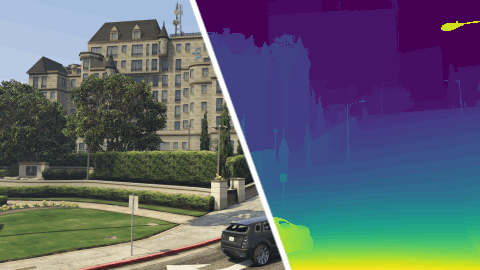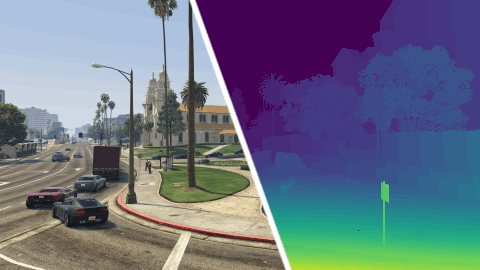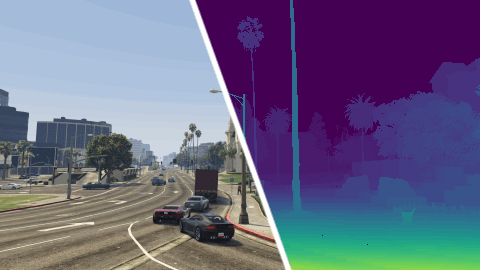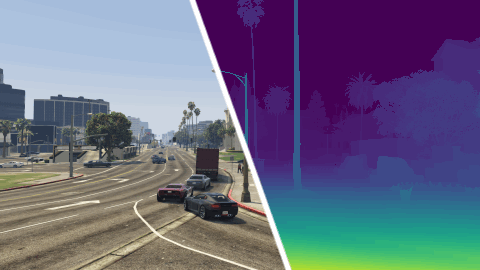
MVS-Synth Dataset is a photo-realistic synthetic dataset prepared for learning-based Multi-View Stereo algorithms. It consists of 120 sequences, each with 100 frames of urban scenes captured in the video game Grand Theft Auto V.[note] The RGB image, the ground truth depth map, and the camera parameters of each frame are provided.
Compared to other synthetic datasets, MVS-Synth Dataset is more realistic in terms of context and shading, and compared to real-world datasets, MVS-Synth provides complete ground truth disparities which cover regions such as the sky, reflective surfaces, and thin structures, whose ground truths are usually missing in real-world datasets.
Data
Three image resolutions are provided. The data is for research and educational use only.
The dataset is hosted on HuggingFace:
Format
The depth maps are stored in EXR format with half-precision floating-point numbers. The zero-disparity pixels (such as sky) are stored as inf. There are no invalid or unavailable depths. Take the reciprocal of depth maps to convert them to disparity maps used in our paper.
The camera parameters are stored in JSON format. Each JSON file contains an object with the following attributes:
extrinsic: A 4×4 nested list representing the world-to-camera extrinsic matrix. Note that the rotation matrices have determinants -1 instead of 1. Further processing may be necessary in some applications.c_xandc_y: The principal point.f_xandf_y: The focal lengths.
The file structure is shown below:
+-- num_images.json
+-- 0000
| +-- depths
| | +-- 0000.exr
| | +-- ...
| | +-- 0099.exr
| +-- images
| | +-- 0000.png
| | +-- ...
| | +-- 0099.png
| +-- poses
| +-- 0000.json
| +-- ...
| +-- 0099.json
+-- 0001
| +...
...
+-- 0119
+...
BibTeX
If you use this dataset in your work, please cite:
@inproceedings{DeepMVS,
author = "Huang, Po-Han and Matzen, Kevin and Kopf, Johannes and Ahuja, Narendra and Huang, Jia-Bin",
title = "DeepMVS: Learning Multi-View Stereopsis",
booktitle = "IEEE Conference on Computer Vision and Pattern Recognition (CVPR)",
year = "2018"
}