DeepMVS: Learning Multi-View Stereopsis
Po-Han Huang1 Kevin Matzen2 Johannes Kopf2 Narendra Ahuja1 Jia-Bin Huang3
1University of Illinois, Urbana Champaign 2Facebook 3Virginia Tech

Abstract
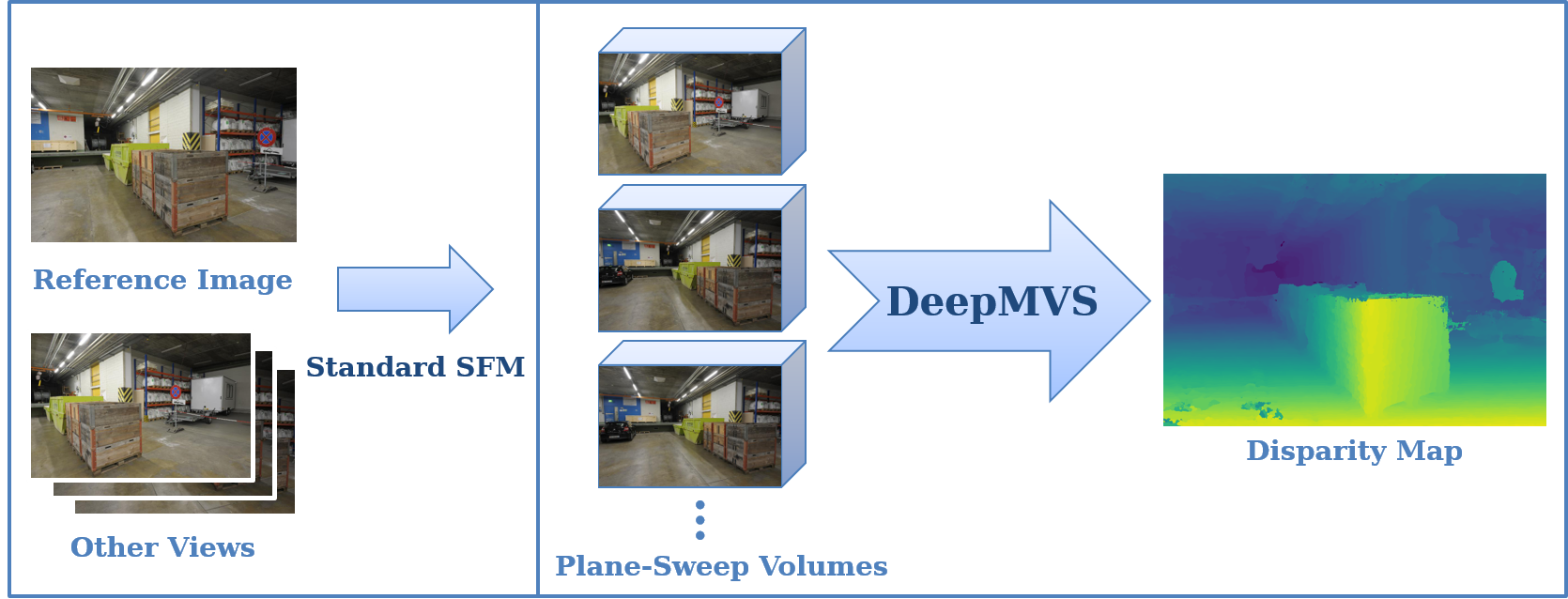
We present DeepMVS, a deep convolutional neural network (ConvNet) for multi-view stereo reconstruction. Taking an arbitrary number of posed images as input, we first produce a set of plane-sweep volumes and use the proposed DeepMVS network to predict high-quality disparity maps. The key contributions that enable these results are (1) supervised training on a photorealistic synthetic dataset, (2) an effective method for aggregating information across a set of unordered images, and (3) integrating multi-layer feature activations from the pre-trained VGG-19 network. We validate the efficacy of DeepMVS using the ETH3D Benchmark. Our results show that DeepMVS compares favorably against state-of-the-art conventional MVS algorithms and other CNN based methods, particularly for near-textureless regions and thin structures.








BibTeX
If you use our code or data, please cite:
@inproceedings{DeepMVS,
author = "Huang, Po-Han and Matzen, Kevin and Kopf, Johannes and Ahuja, Narendra and Huang, Jia-Bin",
title = "DeepMVS: Learning Multi-View Stereopsis",
booktitle = "IEEE Conference on Computer Vision and Pattern Recognition (CVPR)",
year = "2018"
}